第一节课要先安装requests库
在pycharm上面可以搜索直接安装
然后在pycharm上输入
import requests如果没有出现错误,说明下载成功了
接下来我们试试get请求,get请求相当于我们在浏览器按下了一次回车键
import requests
url='https://www.baidu.com/'
html=requests.get(url)
print(html.text)requests里面的get请求,并且把值赋值给html。最后在打印html,最后的.text
相当于打印网页的源代码。
获取的源代码是从百度的<html>到</html>
有的时候网页不仅仅是一个域名,后面会加一些参数,那么这些参数要怎么赋值呢
有两种方法
1.通过params加参数
2.直接写在url里,参数多了就不好用了
import requests
params={'wd':'python'}
url='https://www.baidu.com/s'
html=requests.get(url,params=params)
print(html.text)这样就可以获取到源代码了
post请求是提交资源给页面
传输的参数 get是params,那么post就是data,同样是使用键值对的方式
import requests
url='http://httpbin.org/post'
data={'key':'value'}
html=request.post(url,data=data)
print(html.text)当爬取下来的数据编码和解码不一致的时候,就会产生乱码
import requests
url='https://www.baidu.com/s?wd=python'
html=requests.get(url)
#手工设置
html.encoding='utf8'
#自动识别
html.encoding=html.apparent_encoding
print(html.text)当我们想要爬取到图片、音乐、视频的时候,这三项获取到的就是二进制文本
我们不能使用text来获取,要使用content
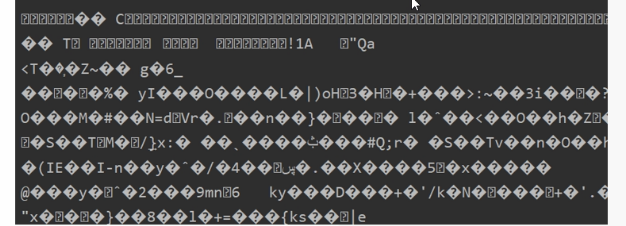
因为图片、音乐、视频使用的是二进制的代码,所以.text识别不了。要用.content就可以打印出来
import requests
url='https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fs5.51cto.com%2Foss%2F202109%2F15%2F1e08b1925d22c89134e792093ce356f2.jpg'
html=requests.get(url)
print(html.content)
with open('1.jpg','wb')as f:
f.wirte(html.content)这样图片就被下载下来了