Beautiful Soup库是一个可以html里提取数据的python库,他能够把单行的html整理成树型结构,每个节点都是python对象,这样就可以方便后面的其他操作
这个是需要单独安装库的,cmd里面安装的方法是
pip install bs4
另外还需要安装一个解析器
pip install lxml
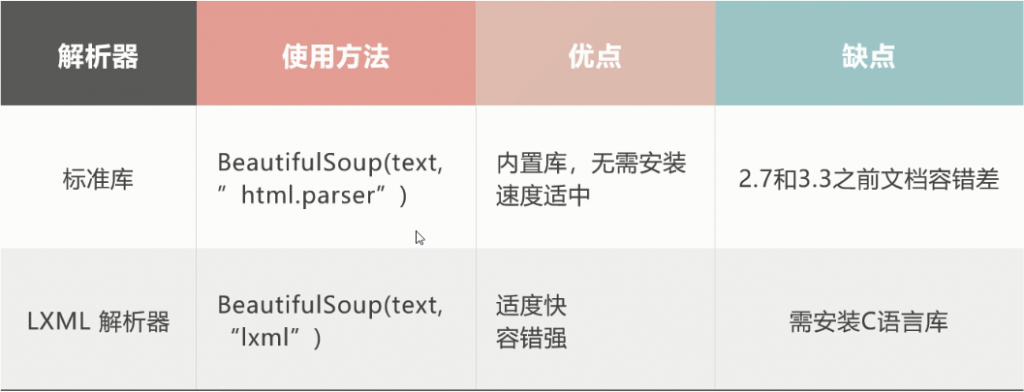
初步理解为,html语言通过beautifulsoup转换成树状结构,然后通过lxml来解析里面的每一个单元结构
最后打印出来
import requests
from bs4 import BeautifulSoup
html = requests.get('https://www.baidu.com/s?wd=python')
html.encoding=html.apparent_encoding
soup = BeautifulSoup(html.text,'lxml')
print(soup.title)
这里因为没有加入headers,所以有个验证,但是代码是正确的
import requests
from bs4 import BeautifulSoup
headers={
'Cookie': 'BAIDUID=83922A2BC374BC8A90E3A2B0EC35585C:FG=1; BIDUPSID=83922A2BC374BC8AE23D84336E85D203; PSTM=1651322845; BD_UPN=13314352; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; BDRCVFR[Fc9oatPmwxn]=mk3SLVN4HKm; delPer=0; BD_CK_SAM=1; PSINO=7; H_PS_PSSID=36309_31253_34812_36167_34584_35978_36074_35801_36236_26350_36303_22159_36061; BA_HECTOR=a42100ak850g8ga0n91h6somn0r; baikeVisitId=01884ce8-48b0-487c-8c28-6f1345230b6a; COOKIE_SESSION=40_0_4_5_6_12_1_0_4_3_334_5_571_0_0_0_1651404497_0_1651412423%7C8%230_0_1651412423%7C1; H_PS_645EC=99447bwxq4XerP0PhxXsQfVJmUaUbRKpFepUSd8Agg6X4YdNXn7X0CjJKrRdBBFEpQov; Hm_lvt_aec699bb6442ba076c8981c6dc490771=1651414096; Hm_lpvt_aec699bb6442ba076c8981c6dc490771=1651414096','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0'
}
html = requests.get('https://www.baidu.com/s?wd=python',headers=headers)
html.encoding=html.apparent_encoding
soup = BeautifulSoup(html.text,'lxml')
for i in soup.select('div.result.c-container h3.c-title a'):
print(i.text)当我们加入了headers,就能过了百度安全验证,先用beautifulsoup把html转化为树状结构,再用解析器解析,最后通过选择器select定位css找到我们需要爬取的内容,最后通过循环,并且只打印内容。
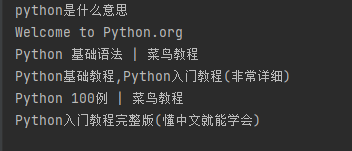
成功抓取百度标题